
Accelerate Data Product Delivery with an Agentic Ingestion Partner
An AI-powered ingestion agent that turns a conversation into production-ready data pipelines — automating source profiling, strategy selection, artefact generation, and validation across every data source, every time.
The Client
A publicly listed global (re)insurance group headquartered in the United States, operating across property, casualty, and specialty lines. The organisation underwrites complex risks for multinational corporations and institutional clients, with a strong presence across North America, Bermuda, Europe, and Asia.
As a large-scale international carrier operating within the Lloyd's market, the company is subject to stringent regulatory and financial reporting requirements. Its global footprint, underwriting complexity, and capital management obligations demand high standards of governance, accuracy, and transparency across regulatory submissions.
As a large-scale international carrier operating within the Lloyd's market, the company is subject to stringent regulatory and financial reporting requirements. Its global footprint, underwriting complexity, and capital management obligations demand high standards of governance, accuracy, and transparency across regulatory submissions.
4
0
9
4
3
7
8
6
4
$
18
4
3
2
7
8
0
4
2
0
B
4
3
2
7
8
0
4
2
0
+
Gross Writeen Premiums
4
0
9
4
3
7
8
6
4
3
0
4
3
2
7
8
0
4
2
0
0
4
3
2
7
8
0
4
2
0
0
4
3
2
7
8
0
4
2
0
+
Employees worldwide
4
0
9
4
3
7
8
6
4
10
0
4
3
2
7
8
0
4
2
0
+
Countries of operation

The Challenge
The organisation's data engineering teams faced an accelerating backlog of ingestion requests across multiple source systems — external Databricks platforms, SQL databases, and file-based landing areas. Each new data source required days of manual work: profiling schemas, writing SQL templates, configuring pipelines, generating DDLs, registering strategies, and validating results across RAW and CLEAN layers.
With no standardised framework and no automated tooling, pipeline quality depended entirely on individual engineer expertise. Naming conventions drifted, ingestion strategies were inconsistently applied, and testing was often skipped under delivery pressure. The result was a growing estate of fragile, poorly documented pipelines that slowed downstream data product development. The organisation needed to industrialise ingestion delivery — making it fast, repeatable, and quality-assured regardless of engineer experience level.10,000 business metrics and required strict adherence to 1,000 validation rules defined by Lloyd’s specifications. Ensuring consistency, traceability, and auditability across this scale of reporting posed a significant architectural and operational challenge.
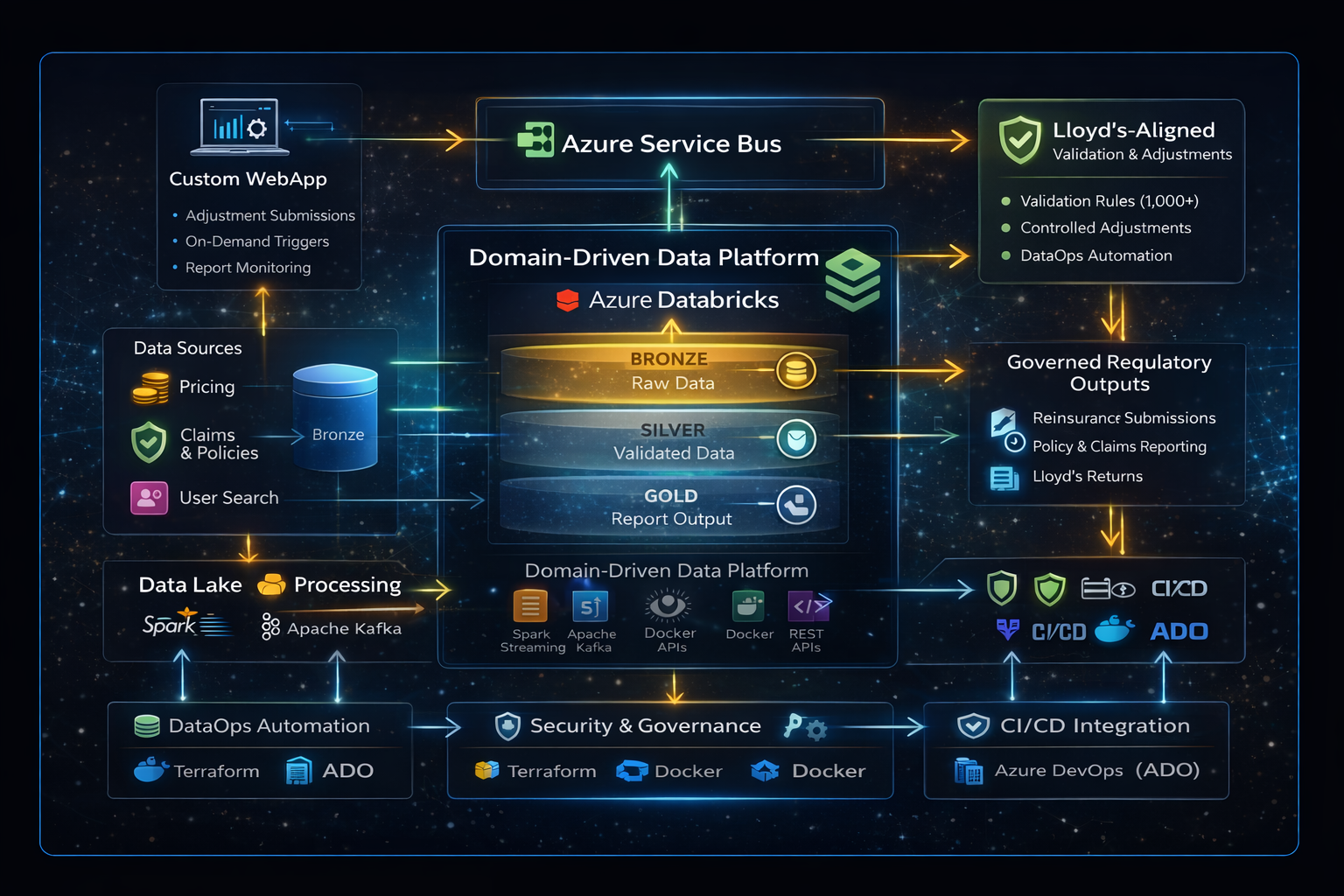
The organisation needed to transition from a manually coordinated, externally managed process to a modern, automated, and internally governed data platform capable of industrialising regulatory production. The objective was not only to internalise reporting, but to design a scalable domain-driven architecture that could support future financial and regulatory use cases beyond Lloyd’s submissions.
With no standardised framework and no automated tooling, pipeline quality depended entirely on individual engineer expertise. Naming conventions drifted, ingestion strategies were inconsistently applied, and testing was often skipped under delivery pressure. The result was a growing estate of fragile, poorly documented pipelines that slowed downstream data product development. The organisation needed to industrialise ingestion delivery — making it fast, repeatable, and quality-assured regardless of engineer experience level.10,000 business metrics and required strict adherence to 1,000 validation rules defined by Lloyd’s specifications. Ensuring consistency, traceability, and auditability across this scale of reporting posed a significant architectural and operational challenge.
The organisation needed to transition from a manually coordinated, externally managed process to a modern, automated, and internally governed data platform capable of industrialising regulatory production. The objective was not only to internalise reporting, but to design a scalable domain-driven architecture that could support future financial and regulatory use cases beyond Lloyd’s submissions.
Our Solution
We designed and deployed an agentic ingestion specialist — an AI-powered agent embedded in the development environment — that guides engineers through the complete end-to-end ingestion workflow via natural language. From a single conversational prompt, the agent profiles the source, recommends the optimal ingestion and cleaning strategy, generates all required pipeline artefacts, runs two automated validation cycles, and commits production-ready code — enforcing engineering standards at every step.
The solution integrates seamlessly with the organisation’s existing Azure data platform and CI/CD tooling, following domain-driven and Medallion-layer conventions to ensure every generated pipeline is consistent, governed, and production-ready from day one.
The solution integrates seamlessly with the organisation’s existing Azure data platform and CI/CD tooling, following domain-driven and Medallion-layer conventions to ensure every generated pipeline is consistent, governed, and production-ready from day one.
Conversational Requirements Capture
Engineers describe the source in plain language. The agent asks targeted questions to determine source type, ingestion mode, partitioning strategy, and cleaning approach — ensuring every required parameter is captured before a single line of code is generated. No specialist knowledge of the underlying platform is required.
Automated Source Profiling & Strategy Recommendation
The agent profiles the source table autonomously — analysing schema, row counts, data size, watermark columns, and change patterns. It classifies the data as Reference, Dimension, or Fact, then recommends the optimal RAW ingestion mode (incremental or full load) and CLEAN layer strategy (SCD Type 2 merge, snapshot history, or complete replacement) with clear, context-aware reasoning.
Zero-Code Artefact Generation
From a confirmed configuration, the agent autonomously generates all 10 required pipeline artefacts: SQL templates, strategy classes, ingest and clean pipelines, RAW and CLEAN DDLs, factory registration, and workflow updates. Zero manual coding is required — the complete ingestion stack is produced in seconds, consistently and to standard.
Human-in-the-Loop Quality Gate
Before any artefacts are generated, the agent presents a complete configuration summary for human review and explicit approval. Engineers verify ingestion mode, partitioning strategy, business keys, and CLEAN layer approach — combining the speed of AI generation with the confidence of expert oversight. No code is produced without a human sign-off.
Automated Two-Run Validation
The agent executes two full ingestion cycles per dataset and validates both using automated tooling — checking row counts, partition structure, SCD column integrity, and strategy-specific behaviour. The first run establishes the baseline; the second confirms the strategy works correctly under real conditions. No code is committed until both runs pass.Terraform and CI/CD pipelines in Azure DevOps (ADO) to automate platform provisioning and controlled promotion of data products across dev, qas, uat, prod, and dre environments.
Governance & Observability
Every pipeline generated by Copilot exposes end-to-end data lineage, quality metrics, and reconciliation summaries through Unity Catalog and Azure Monitor integration. Data product owners and platform teams gain full visibility into the health and trustworthiness of the data estate, supporting auditability and proactive issue detection across all domains.
The Value
The agentic data engineering platform transformed the organisation's ability to deliver trusted data products at scale. What previously required a full day of manual engineering work is now completed in under 10 minutes — 50 new data sources that once took 50 days to ingest are now onboarded in a single day. Built-in quality controls and domain alignment are enforced automatically, freeing engineers to focus on higher-value data product ownership.

4
0
9
4
3
7
8
6
4
1
4
4
3
2
7
8
0
4
2
0
4
4
3
2
7
8
0
4
2
0
x
Faster Pipeline Delivery
What took a full day of manual engineering now completes in under 10 minutes. 50 new data sources previously requiring 50 days to onboard are now delivered in a single day.
4
0
9
4
3
7
8
6
4
9
5
4
3
2
7
8
0
4
2
0
%
Reduction in Data Quality Issues
Built-in reconciliation and automated quality gates eliminated 95% of data issues previously discovered by downstream consumers, restoring trust across the data estate.
4
0
9
4
3
7
8
6
4
7
0
4
3
2
7
8
0
4
2
0
+
Engineering Capacity Unlocked
70% of engineering time previously spent on manual pipeline coding was redirected to data product ownership, domain design, and strategic data initiatives.
Natural Language Requirements Interface
The Copilot agent guides developers through requirements capture entirely in natural language. Through a conversational interface, it asks targeted questions to elicit ingestion strategies, business rules, quality thresholds, and domain context — ensuring nothing is missed before a single line of code is generated. No specialist knowledge of the underlying platform is required to define a production-grade data product.
Zero-Code Delivery with Human-in-the-Loop
Developers define requirements; the agent writes all the code. Every generated pipeline is automatically validated against the organisation’s engineering standards — linting, formatting, pre-commit hooks, and code quality tooling — before being surfaced to a human reviewer for final approval. This human-in-the-loop gate ensures alignment with architectural principles and domain intent, combining the speed of AI generation with the confidence of expert oversight.
Engineers Elevated to Data Product Owners
With the agent handling all pipeline generation, data engineers are freed from manual coding entirely. Their role shifts from writing boilerplate ingestion and transformation logic to owning data products, defining domain requirements, and verifying agent output. The result is a higher-skilled, higher-impact engineering function — one focused on data strategy rather than implementation detail.

Talk Less. Build More.
© 2026 All rights reserved